The following is a look into using REGEX and LIKE in the MAPublisher Expression Builder.
Expression Builder is a key component of the GIS tools that make MAPublisher a powerful cartographic solution. It can be accessed in the following panels:
- MAP Attributes "Edit Schema", "Derive Value from Expression"
- MAP Attributes "Apply Expression"
- MAP Stylesheets "Edit MAP Stylesheet", "Style Rules: Expression"
- MAP Selections "New MAP Expression"
- MAP Selections "Edit MAP Selection"
- Split Layer tool
The REGEX function is one of the advanced functions--one which deserves some extra attention. Here at Avenza support, we have had many opportunities to build REGEX expressions to assist MAPublisher users in leveraging their datasets. REGEX is an abbreviation for Regular Expression and is a tool for matching substrings within text strings. In this discussion, strings are the values found in each cell of the MAPublisher attribute table, and substrings are smaller patterns that we wish to find within the strings. For example, "land" is a substring found twice in "Falkland Islands", and "23" is a substring found in the string "4562378". A REGEX expression looks like this: REGEX(Column_Name,"expression in quotes"), the expression in the quotes can contain the text to be searched for written using alphanumeric characters or any of the following metacharacters:
., [ alphanumeric set of characters], w, s, d, W, S, D, t, {n}, {n,}, {n,m}, *, +, ?, ^, $, b, B
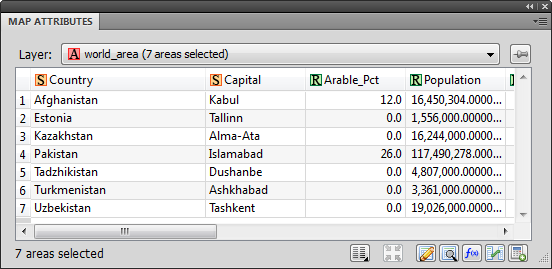
The dataset we will be working with has an area object and attribute information for every country in the world. It's named world.mif and can be found in the Tutorial Data folder of your MAPublisher installation. Import this file into a new Illustrator document to REGEX's more basic operations accomplish what the LIKE operator can do. Let's compare using lowercase "z": both REGEX(Country,"z") and LIKE(Country,"z") return the same query results:
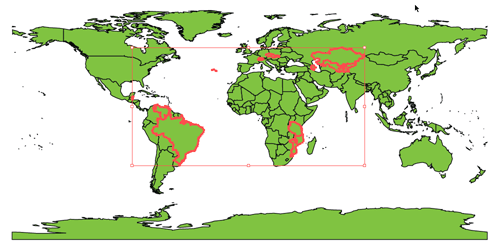
Similarly, both REGEX(Country,"Z") and LIKE(Country,"Z") select artwork with a capital "Z" in the Country field of the attribute table:
If we wanted the Country field entries that contained both capital and lower case "z" we would have to use a character set. Both the LIKE operator and REGEX support character sets, and use square brackets to signify them. The following expressions, LIKE(Country,"[zZ]") and REGEX(Country,"[zZ]") return this result:
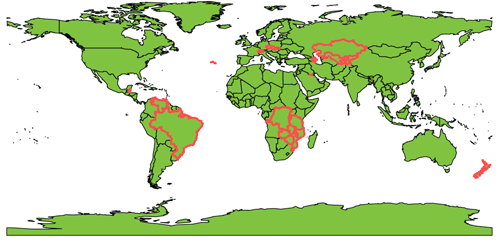
Both LIKE and REGEX can be used to search for wildcards. For a single wildcard character LIKE uses "?" while REGEX uses "." The following expressions: LIKE(Country,"st?n") and REGEX(Country, "st.n") will return all the "stan" countries (Pakistan, Afghanistan, etc.) along with Estonia.
The "*" character in the LIKE operator will search for any number of characters within the queried field. Therefore LIKE(Country,"*") would return every country, and LIKE(Country, "st*n") would return all the countries of the previous LIKE(Country,"?") query, along with Liechtenstein, Western Sahara, and Western Samoa.
Of course, this can also be performed with the REGEX operator, albeit with more awkward syntax. The REGEX equivalent of LIKE(Country,"st*n") from the previous query would be, REGEX(Country,"st[a-z]*") and LIKE(Country,"st?n").
Performing an expression builder query for the substring "land" using REGEX(Country, "land") returns 23 results: countries that end in "land", such as Thailand and Switzerland, along with all countries with Islands in their names (the Cook Islands, or the Canary Islands). How do we query only those results that end in "land"? REGEX has functions to query for substring placement within strings. We use the "$" symbol to query substrings at the end of a string, so that REGEX(Country, "land$"), will return Ireland and Iceland, but not the Solomon Islands.
Similarly, to search for substrings that occur at the beginning of the string, the "^" symbol is used. If you wanted to find all nations that began with "St", without returning all nations with an "st" combination in their names, you would write a REGEX expression like this: REGEX(Country, "^St").
The \b operator will search for specific words (sub-strings with non_character boundaries like spaces or bounded by the beginning or end of the string). Hence, a search like REGEX(Country,"\b[Nn]ew\b"), will return results like New Zealand and New Caledonia, ignoring the occurrence of New or new within other words.
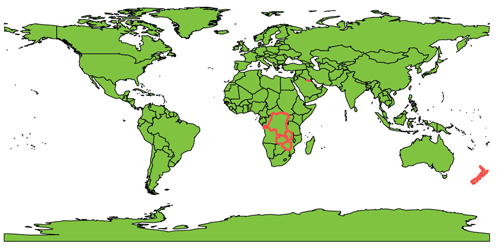
The inverse of the \b metacharacter is the \B, which returns sub-strings that are not to be found at the beginning or end of strings, or at the beginning or ending of words within fields. Thus a query such as REGEX(Country,"\Bst\B") would return countries with an "st" combination in their names that do not end or begin any word:

The power of REGEX comes in creating powerful and simple expressions. Good use of REGEX is in selecting intervals of contour lines. Consider a situation where you would like to select and delete all contours at odd intervals, with values such as intervals, all contours valued 10, 30, 50, 70, 90, 110, etc. The inefficient way to do this would be with an enormous expression that looks like this:
This type of expression has many opportunities for syntax error or the possibility of neglecting to input an interval as the number of query terms grows. This can be written much more efficiently as follows:

The vertical line between values is the "pipe" character that serves as an "OR" operator (found above the "\" key), and the $ indicates to only choose the value if it is at the end of a string (will pick 10 and 310 but not 1040).
How far can you take REGEX? That depends entirely on the complexity of your data. Now that you are familiar with basic REGEX functions, websites such as http://regexlib.com/ will show you just how many uses REGEX can be put to.
Comments
0 comments
Please sign in to leave a comment.