The MAPublisher Edit Expression tool is used for the entry and editing of expressions. It is used in a number of locations such as creating new attribute values and properties, making selections, or applying styles. Expressions are built using a combination of names, operators, and functions. Edit Expression is available for a number of tools throughout MAPublisher:
|
MAPublisher tool |
Description |
|
Edit Schema |
To create or edit an expression for the generation of values in an attribute or column. (MAP Attributes panel > Edit Schema > Derive value from expression) |
|
Apply Expression |
To apply an expression to an attribute or property column for selected art only. (MAP Attributes panel > Apply Expression) |
|
New/Edit MAP Selection |
To create or edit expression criteria for use in selecting map data. (MAP Selections panel > New/Edit MAP Selection) |
|
Edit Stylesheet Theme |
To create or edit an expression for use in styling map data. (MAP Themes panel > Edit [Stylesheet Theme name] > Advanced Expression mode |
Building Expressions
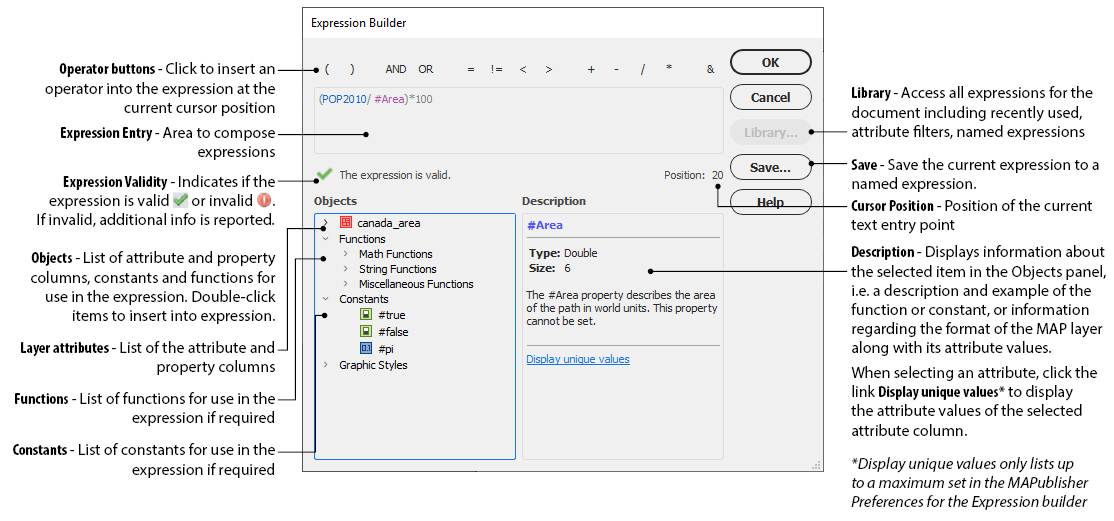
Expressions can be built by typing or by clicking the operator buttons and items in the Objects list (attribute name and values, constants, and functions). These items are colour coded for easy identification: attribute names in purple, string values in orange, operators and numerical values in grey, constants in green, and functions in black. Click any of the operator buttons or double-click an item from the Objects list to insert it into the expression.
It is recommended to use the interface rather than the keyboard to build expressions, to guarantee functions are formatted correctly (e.g. with brackets and appropriate case) and for attribute values of type strings, quotation marks are added automatically. Note that expressions are case-sensitive. For string comparison, all string values can be converted to the same case using the appropriate function (LOWER(“string”) or UPPER(“string”)).
Validity
The validity of the expression will be displayed below the Expression Entry text area and will be updated as the expression is built. The Expression Validity icon will report if the expression entered is valid (green checkmark). Otherwise, it will report invalid (red exclamation) and include additional warning notes.
Operator Buttons
Click to insert an operator at the current cursor position. Available operators are as follows:
|
Operator |
Description |
|
( |
Open clause operator |
|
) |
Close clause operator |
|
AND |
Logical AND operator |
|
OR |
Logical OR operator |
|
= |
Logical equal to comparator |
|
!= |
Logical not equal to comparator |
|
< |
Logical less than comparator |
|
> |
Logical greater than comparator |
|
+ |
Mathematical addition operator |
|
- |
Mathematical subtraction operator |
|
/ |
Mathematical division operator |
|
* |
Mathematical multiplication operator |
|
& |
Text concatenate operator |
Expression Components
Items in the Objects list are divided into three function categories: math, string, and miscellaneous. Information on a selected item is displayed in the Description panel. Double-click to insert an object at the current cursor position.
|
|
Function |
Description |
|
|
ABS |
Absolute value of a number |
|
|
ACOS |
Inverse of the cosine of an angle |
|
|
ASIN |
Arcsine of an angle |
|
|
ATAN |
Arctangent of an angle |
|
|
CONTAINS |
True if source string contains search string |
|
|
COS |
Cosine of an angle |
|
|
DEGREES |
Converts values from radians to degrees |
|
|
ENDSWITH |
Returns true the source string ends with the suffix string |
|
|
FIXED |
Numbers as string values |
|
|
FROM_HEX |
Returns the decimal value of the hexadecimal string |
|
|
IF |
Conditional statement |
|
|
IF_CASE |
Conditional statement based on multiple cases |
|
|
LEFT |
Extracts the first N characters of a string |
|
|
LENGTH |
Returns the number of characters in a string |
|
|
LIKE |
Searches the source string using wildcards |
|
|
LOG |
Gets the logarithm of the value (base 10 log) |
|
|
LN |
Gets the natural logarithm (base e log, e = 2.718281828) |
|
|
MAX |
Returns biggest attribute value |
|
|
MAX_COLNAME |
Returns name of attribute which has biggest value |
|
|
MIN |
Returns smallest attribute value |
|
|
MIN_COLNAME |
Returns name of attribute which has smallest value |
|
|
LOWER |
Converts string to lowercase |
|
|
MID |
Extracts N characters of a string from a specified location |
|
|
MOD |
Gets the remainder of numerator divided by divisor |
|
|
NUMBER |
String values as numbers |
|
|
POW |
Base to the power of an exponent |
|
|
PROPER |
Strings converted to capital case |
|
|
RADIANS |
Converts values from degrees to radians |
|
|
RAND |
Generates a random value between zero (min) and value (max) |
|
|
REGEX |
Searches the source string using a regular expression |
|
|
RIGHT |
Extracts the last N characters of a string |
|
|
ROUND |
Rounds to specified decimals of precision |
|
|
ROUNDDOWN |
Rounds down to the specified decimals of precision |
|
|
ROUNDUP |
Rounds up to specified decimals of precision |
|
|
SEARCH |
Returns the position of a character in a string |
|
|
SIN |
The sine of an angle |
|
|
SPLIT |
Splits a string and extracts the indexed part of it |
|
|
SQRT |
Square root of a value |
|
|
STARTSWITH |
Returns true if the source string starts with the prefix string |
|
|
SUBSTITUTE |
Replaces a set of characters by another in a string |
|
|
SUBSTITUTE_RX |
Replaces a regular expression by characters in a string |
|
|
TAN |
Tangent of an angle |
|
|
TO_HEX |
Returns hex string version of value |
|
|
TRIM |
Removes all spaces in a text (except single ones between words) |
|
|
UPPER |
Converts string to uppercase |
|
Constants #false Boolean false value #true Boolean true value #pi π numerical value (3.141592) |
||













































 String values are case-sensitive and must be entered in double quotes (“...”).
String values are case-sensitive and must be entered in double quotes (“...”).
 For functions using indexes for text position (MID, SEARCH and SPLIT), the first index number is 0.
For functions using indexes for text position (MID, SEARCH and SPLIT), the first index number is 0.
 Layers may vary depending on the tool. For Edit Schema, Apply Expression and New/Edit MAP Selections, the current layer is displayed. In the Edit Stylesheet Theme, all layers hosted by the stylesheet are displayed.
Layers may vary depending on the tool. For Edit Schema, Apply Expression and New/Edit MAP Selections, the current layer is displayed. In the Edit Stylesheet Theme, all layers hosted by the stylesheet are displayed.
 Unique values contained in each attribute column can be viewed in the Description panel.
Unique values contained in each attribute column can be viewed in the Description panel.
Examples of Basic Expressions
More examples of each individual function can be found in the Expression Builder dialog box. Expand the Expression Components, choose a function or constant on the Objects list and the Description tab is updated with explanations and examples.
Apply Expression
|
Expression |
Result |
|
“Ontario” (applied to column = NAME) |
All items are assigned the value “Ontario” in the NAME column. |
|
“MAP Area 01” (applied to column = #Style) |
All area items are assigned the value “MAP Area 01” in the #Style column and are assigned the Graphic Style “MAP Area 01” on the page. |
|
45 (applied to column = #Rotation) |
All point items are assigned the value 45 in the #Rotation column and are rotated to 45° on the page. |
MAP Selections
|
Expression |
Result |
|
NAME = “Ontario” |
All items with the value “Ontario” in the NAME column are selected. |
|
POPULATION < 1000000 |
All items with values less than one million in the POPULATION column are selected. |
|
NAME = “Ontario” OR NAME = “Alberta” |
All items with the value “Ontario” OR “Alberta” in the NAME column are selected. |
|
NAME = “Ontario” AND POPULATION < 1000000 |
Only the items containing the value “Ontario” in the NAME column AND values less than one million in the POPULATION column are selected. |
MAP Theme Stylesheet
|
Expression |
Result |
|
NAME = “Ontario” |
All items with the value “Ontario” in the NAME column are assigned the selected style. |
|
POPULATION < 1000000 |
All items with values less than one million in the POPULATION column are assigned the selected style. |
|
NAME = “Ontario” OR NAME = “Alberta” |
All items with the value “Ontario” OR “Alberta” in the NAME column are assigned the selected style. |
|
NAME = “Ontario” AND POPULATION < 1000000 |
Only items containing the value “Ontario” in the NAME column AND values less than one million in the POPULATION column are assigned the selected style. |
Edit Schema
|
Expression |
Result |
|
LOWER(NAME) (applied to column = name) |
All items in column name are assigned the value of the column NAME in lower case (e.g. “ontario” for “Ontario”) |
|
PROPER(name) (applied to column = Proper_name) |
All items in Proper_name are assigned the value of the column name in proper case (or capital case) (e.g. “Ontario” for “ontario”) |
|
TRIM(JOINING_COLUMN) |
All items are trimmed with all spaces except single ones between words (e.g. " Route 66 " becomes "Route 66"). This is particularly useful prior to using the Join Table function because extra spaces at the beginning, end or in between words will cause the join to fail. |
Examples of Complex Expressions
MAP Selections or MAP Theme Stylesheet
|
Expression |
Result |
|
LIKE (NAME, “*New*”) |
All items with the string of letters "New" in the NAME column are selected (e.g. “New Brunswick” and “Province of Newfoundland”) |
|
STARTSWITH (NAME, “o”) |
All items that start with the letter “o” (“Ontario”) are selected. |
Edit Schema
|
Expression |
Result |
|
ROUND((POPULATION/ AREA ),3) (applied to column=density) |
All items are calculated as “population divided by area”, rounded to three decimals. |
|
IF_CASE("null", VALUE>0,"positive",VALUE<0,"negative") |
A default status of "null" is assigned unless the value is strictly greater than or less than zero. |
|
SUBSTITUTE_RX(ROAD_NAME,"\D","") |
All non-digit characters (\D is the regular expression for non-digit character) are replaced by nothing (two double-quotes indicate that the new string is blank), therefore only numerical values are kept. For example, if the ROAD_NAME equals "Route 66", the result is "66". This can be useful to prepare an attribute table prior to labeling roads with road numbers rather than road names. |
|
SPLIT(GEOLOGIC_UNIT,"(",0) |
All items containing one or more open parenthesis are split in several text blocks (as many as there are open parenthesis, plus one), and returns the first block found (index 0). For example, if GEOLOGIC_UNIT equals "Qmw(Qc)", the result is "Qmw". |
|
SUBSTITUTE(SPLIT(GEOLOGIC_UNIT,"(",1),")","") |
Removes all closing parenthesis (i.e substitute all closing parenthesis with nothing) in the result of the same SPLIT as above, that returns the second text block found (index 1). For example, if GEOLOGIC_UNIT equals "Qmw(Qc)", the result is "Qc": first the SPLIT function returns "QC)" and then ")" is removed with a SUBSTITUTE. |
Expression Library
Expressions already entered in the MAP Attributes panel, MAP Themes stylesheets, or MAP Selections panel can be reused by selecting them from the Expression Library.
Expressions are sorted into three categories: Recent, Named Expressions, or Attribute Selections. One or more entries can be selected per category. Click the Insert button to add the selection to the Expression Builder—multiple selections are concatenated with the AND statement.
 It is not possible to insert multiple expressions from different categories at once.
It is not possible to insert multiple expressions from different categories at once.
Recent Expressions
Expressions in the Recent tab of the Expression Library are expressions saved in memory for the time of the Adobe Illustrator session (they are reset if the document is closed). They correspond to expressions recently typed in the Expression Builder from the MAP Attributes panel or MAP Themes stylesheets but were not saved as a Named Expression.
To delete a recent expression, select it in the Expression Library dialog box and click the Delete button.
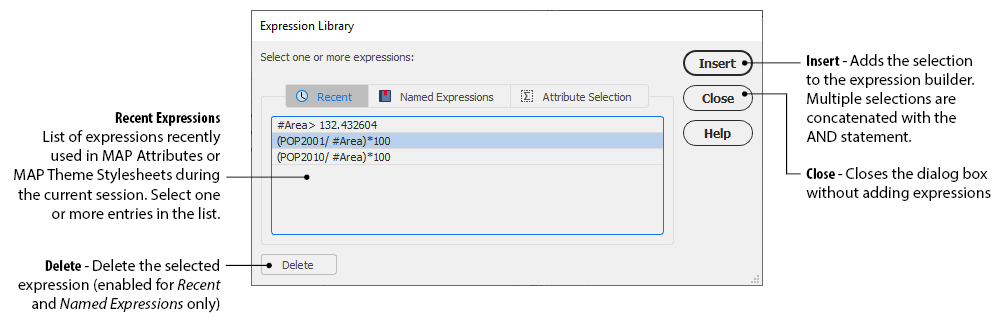
 In the MAP Attributes panel, expressions are saved in the recent list only when the Edit Schema dialog box is closed.
In the MAP Attributes panel, expressions are saved in the recent list only when the Edit Schema dialog box is closed.
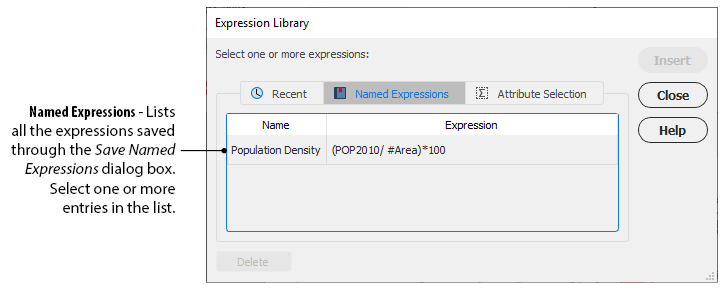
Named Expressions
Expressions entered in the Expression Builder can be saved as a Named Expression by clicking the Save button. Unlike the Recent expressions, named expressions are saved within the Adobe Illustrator document. They are listed in the Named Expressions tab of the Expression Library. To delete a named expression, select it in the Expression Library dialog box and click the Delete button.
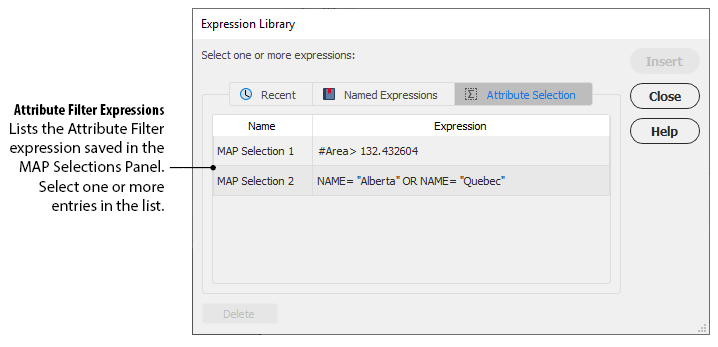
Attribute Selection Expressions
The Attribute Selection tab of the library lists the expressions in use in the MAP Selections with the type Attribute Selection. See details on the MAP Selections panel. Attribute Selection expressions cannot be deleted from the Expression Library (only the MAP Selections panel).
Comments
0 comments
Please sign in to leave a comment.